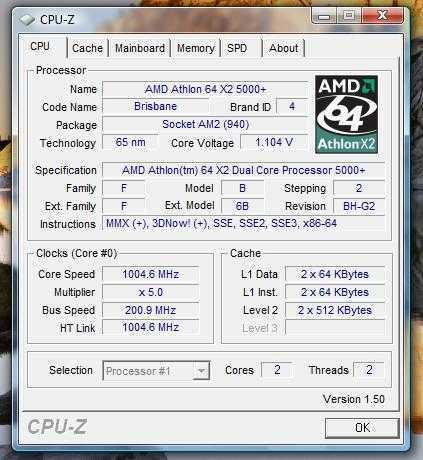
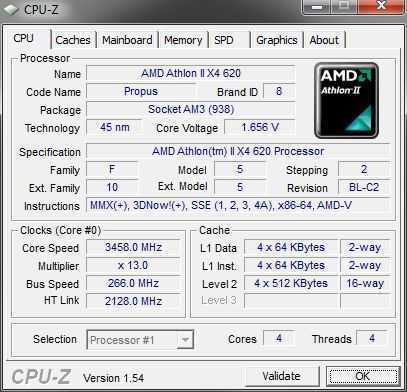
Вопрос №3: что с виртуалками, созданными на Intel?
Я не люблю простые ответы на сложные вопросы, и вместо того, чтобы просто написать «оно будет работать», максимально усложню себе задачу. Во-первых, я возьму хост на Intel Xeon-D 2143IT, и поставлю на него ESXi 6.7 U1, не самую свежую версию гипервизора, в то время как на AMD-машине будет установлена ESXi 6.7 U3. Во-вторых, в качестве гостевой операционной системы я буду использовать Windows Server 2016, а к этой операционной системе я отношусь ещё более предвзято, чем к FreeBSD (вы помните, выше по тексту я высказывал своё «фи»). В-третьих под Windows Server 2016 я запущу Hyper-V используя вложенную виртуализацию, и внутри проинсталлирую ещё один Windows Server 2016. Фактически, я эмулирую мултитанантную архитектуру, в которой Cloud-провайдер сдаёт в аренду часть своего сервера под гипервизор, который тоже можно сдавать в аренду или использовать под VDI среду. Здесь сложность в том, что VMware ESXi передаёт в Windows Server функции виртуализации процессора. Это чем-то напоминает проброс GPU в виртуалку, только вместо PCI платы — любое количество CPU ядер, и память резервировать не надо: прелесть, да и только. Конечно, где-то там, за кадром, я уже перенёс с Intel-овского хоста на EPYC и шлюз Pfsense (FreeBSD), и несколько Linux-ов, но хочу себе сказать: «если эта конструкция заработает, то всё заработает»
Теперь самое важное: устанавливаю все апдейты на Windows Server 2016, и выключаю виртуалку, открывая VMware VSCA. Очень важно — виртуалку нужно именно выключить в состояние Off, ведь если та, дальняя ВМ в Hyper-V при выключении Windows Server сохранится в состояние «Saved», на AMD-сервере она не запустится и нужно будет выключать её, нажимая кнопку «Delete state», что может привести к потере данных
AMD-лихорадка в самом разгаре
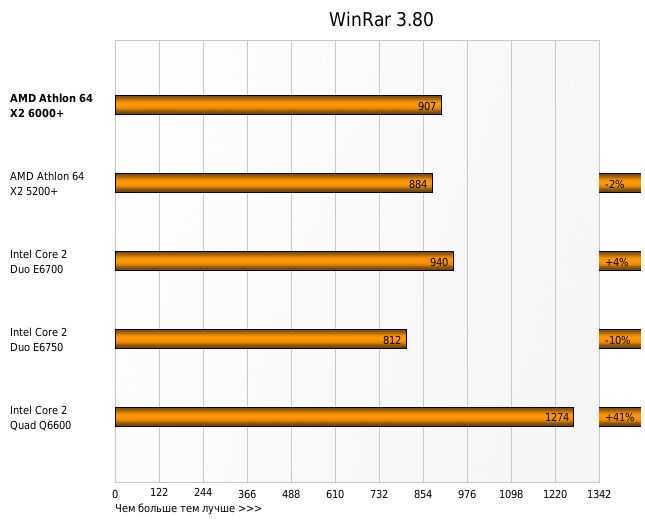
Сегодня с уверенностью можно сказать, что астрологи объявили 2019 год — годом AMD. Компания празднует один успех за другим, процессоры Ryzen для настольных ПК выбиваются в лидеры по продажам среди энтузиастов, чиплетная компоновка позволяет выпустить 1-сокетный сервер с 64 ядрами, серверные процессоры EPYC с ядром Rome устанавливают один мировой рекорд производительности за другим, недавно пополненные результатами рендеринг-бенчмарка Cinebench, а всего таких рекордов уже набралось более сотни (это, кстати, тема для отдельной статьи). Вот некоторые любопытные сравнения из маркетинговых материалов AMD:
Даже VMware в своём блоге подтвержает, что 1-сокетные конфигурации стали достаточно мощными для определённых задач.
Акции AMD выросли с начала года в два раза, и листая заголовки статей, ты ощущаешь себя словно в другой реальности: про AMD — только хорошее, а что же Intel?
Вчерашний законодатель IT-моды сегодня вынужден отбиваться от проблем в области безопасности, снижая цены на старшие процессоры и вкладывая сумасшедшие 3 миллиарда долларов в демпинг и маркетинг для противостояния AMD. Акции Intel не растут, рынок захвачен AMD-лихорадкой.
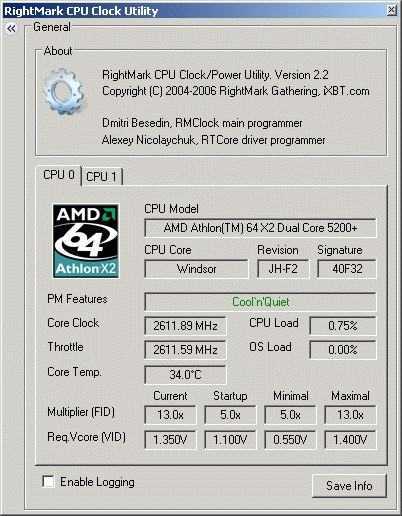


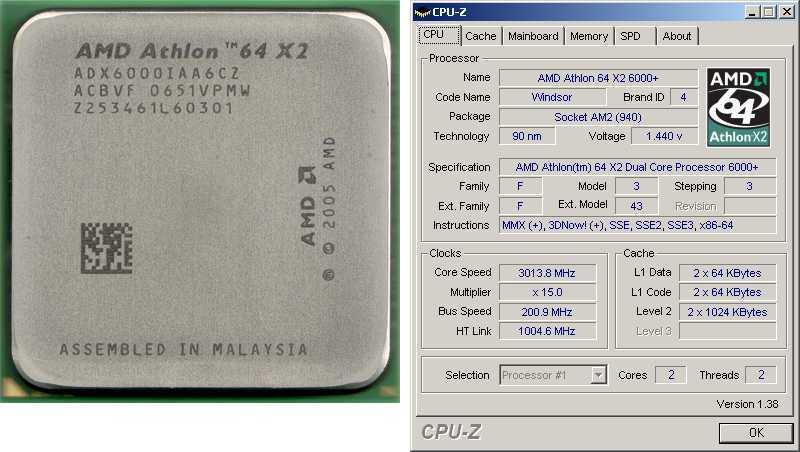





Вопрос №2: что с совместимостью с VMWare vSphere
Поскольку для AMD EPYC родной средой обитания являются «облака», все cloud-операционные системы поддерживают эти процессоры без нареканий и без ограничений. И здесь недостаточно просто сказать, что оно «запускается и работает». В отличие от Xeon-ов, процессоры EPYC используют чиплетную компоновку. В случае с первым поколением (серия 7001) на общем корпусе CPU имеются четыре отдельных чипа со своими ядрами и контроллером памяти и может произойти такая ситуация, когда виртуалка использует вычислительные ядра, принадлежащие одному NUMA-домену, а данные лежат в планках памяти, подключённых к NUMA-домену другого чипа, что вызывает лишнюю нагрузку на шину внутри CPU. Поэтому производителям ПО приходится оптимизировать свой код под особенности архитектуры. В, частности, в VMWare научились избегать таких перекосов в распределении ресурсов для виртуальных машин, и если вас интересуют подробности, рекомендую почитать эту статью. К счастью, в EPYC 2 на ядре Rome этих тонкостей компоновки ввиду особенностей компоновки нет, и каждый физический процессор можно инициализировать как единый NUMA-домен.
У тех, кто начинает интересоваться процессорами AMD часто возникают вопросы: а как EPYC будет взаимодействовать с продукцией конкурентов в области виртуализации? Ведь в области машинного обучения пока что безраздельно властвует Nvidia, а в сетевых коммуникациях — Intel и Mellanox, который нынче часть Nvidia. Хочу привести один скриншот, на котором указаны устройства, доступные для проброса в среду виртуальной машины, минуя гипервизор. Учитывая, что AMD EPYC Rome имеет 128 линий PCI Express 4.0, вы можете устанавливать 8 видеокарт в сервер и пробрасывать их в 8 виртуальных машин для ускорения работы Tensorflow или других пакетов машинного обучения.
Давайте сделаем небольшое лирическое отступление и настроим наш мини-ЦОД для нужд машинного обучения с видеокартами Nvidia P106-090, не имеющими видеовыходов и созданными специально для GPU-вычислений. И пусть злые языки скажут, что это «майнинговый огрызок», для меня это «мини-тесла», прекрасно справляющаяся с небольшими моделями в Tensorflow. Собирая небольшую рабочую станцию для машинного обучения, установив в неё десктопные видеокарты, вы можете заметить, что виртуалка с одной видеокартой запускается прекрасно, но чтобы вся эта конструкция заработала с двумя и более GPU, не предназначенными для работы в ЦОД, надо изменить метод инициализации PCI-E устройства в конфигурационном файле VMware ESXi. Включаем доступ к хосту по SSH, подключаемся под аккаунтом root
и в открывшемся файле в конце находим
и прописываем (вместо ffff будут ваши ID устройства)
После чего перегружаем хост, добавляем видюхи в гостевую операционную систему и включаем её. Устанавливаем/запускаем Jupyter для удалённого доступа «а-ля Google Colab», и убеждаемся, что обучение новой модели запущено на двух GPU.







Когда-то мне нужно было оперативно посчитать 3 модели, и я запускал 3 виртуалки Ubuntu, пробросив в каждую по одному GPU, и соответственно на одном физическом сервере одновременно считал три модели, чего без виртуализации с десктопными видеокартами никак не сделаешь. Только представьте себе: под одну задачу вы можете использовать виртуалку с 8 GPU, а под другую — 8 виртуалок, каждая из которых имеет 1 GPU. Но не стоит выбирать игровые видеокарты вместо профессиональных, ведь после того, как мы изменили метод инициализации на bridge, как только вы выключите гостевую ОС Ubuntu с проброшенными видеокартами, повторно она уже не запустится до рестарта гипервизора. Так что для дома/офиса такое решение ещё терпимо, а для Cloud-ЦОД с высокими требованиями к Uptime — уже нет.
Но это не все приятные сюрпризы: поскольку AMD EPYC — это SoC, ему не нужен южный мост, и производитель делегирует процессору такие приятные функции, как проброс в виртуалку SATA контроллера. Пожалуйста: здесь их два, и один вы можете оставить для гипервизора, а другой отдать виртуальному программному хранилищу данных.
К сожалению я не могу показать на живом примере работу SR-IOV, и для этого есть причина. Я оставлю эту боль «на потом» и изолью душу дальше по тексту. Эта функция позволяет пробросить физически одно устройство, такое как сетевую карту сразу в несколько виртуальных машин, например, Intel X520-DA2 позволяет делить один сетевой порт на 16 устройств, а Intel X550 — на 64 устройства. Вы можете физически пробросить один адаптер в одну виртуалку несколько раз для того, чтобы пошаманить с несколькими VLAN-ами… Но как-то эта возможность не сильно находит применение даже в cloud-средах.
Вопрос №5: почему всем плевать на вопрос №4?
Допустим, у нас есть банк или авиакомпания, которая серьёзно решила снизить OPEX за счёт экономии на лицензиях, уходя с Xeon E5 на EPYC 2. В таких компаниях отказоустойчивость является критичной, и достигается не только за счёт резервирования средствами кластеризации, но и за счёт приложения. Это значит, что в самом простом случае, какая-нибудь там MySQL работает на двух хостах в режиме Master/Slave, а распределённая база данных NoSQL вообще допускает отвал одного из узлов без остановки своей работы. И уж здесь совсем нет проблем остановить резервный сервис, перенести его куда требуется и загрузить заново. И чем крупнее компания, чем важнее для неё отказоустойчивость, тем большую гибкость допускают её IT-ресурсы
То есть, там где к IT мы относимся как к сервису, у нас резервируется сам сервисный софт, не важно где и на какой платформе он работает: в Москве на VMware или в Никарагуа на Windows.
Совсем другое дело — облачные провайдеры типа Mail.ru, Yandex, Облакотека, Selectel… Для них продукт — это работающая виртуальная машина с аптаймом 99.99999%, и выключить клиентский ВМ ради переезда на EPYC — нонсенс. Но и они не рвут на себе волосы от отсутствия живой миграции между Intel и AMD, и дело тут в философии построения ЦОДа. В нашей статье «Секреты профессионалов: как масштабируют ЦОД облачные провайдеры» представитель компании «ИТ-Град» (входит в группу МТС) рассказал, что облачные ЦОДы строятся по принципу «кубиков», или «островков». Допустим, один «кубик» — это вычислительный кластер на абсолютно одинаковых серверах + СХД, которая его обслуживает. Внутри этого кубика происходит динамическая миграция виртуалок, но сам кластер никогда не расширяется и виртуалки с него на другой кластер не мигрируют. Естественно, что кластер, построенный на Intel, всегда и будет оставаться таким, и в одно время либо просто будет модернизирован (все серверы заменят на новые), либо утилизирован, а все ВМ переедут на другой кластер. Но апгрейды/замены конфигураций внутри «кубика» не происходят.





|
Николай Араловец, cтарший системный инженер облачного провайдера «ИТ-ГРАД» (входит в Группу МТС) • Мне видится грамотным подход к сайзингу исходя из определения «кубика» для вычислительного узла (compute node) и хранилища данных (storage node). В качестве вычислительных кубиков выбирается аппаратная платформа с определенным числом ядер CPU и заданным объёмом памяти. Исходя из особенностей платформы виртуализации делаются прикидки сколько «стандартных» VM можно запустить на одном «кубике». Из таких «кубиков» набираются кластера/пулы где могут быть размещены VM с определенными требованиями к производительности. • Базовый принцип сайзинга заключается в том, что все серверы в рамках пула ресурсов — одинаковые по мощности, соответственно и стоимость их одинакова. Виртуальные машины не мигрируют за рамки кластера, по крайней мере, при штатной эксплуатации в автоматическом режиме. |
И если захочет Cloud-провайдер сэкономить на лицензиях и вот просто на железе в пересчёте на CPU ядро, то он просто поставит отдельный «кубик» из десятка-другого серверов на AMD EPYC, настроит СХД и введёт в эксплуатацию. Так что даже для облачников не имеет значения, что клиентскую виртуальную машину нельзя перенести наживую с Intel на AMD: у них просто не возникает таких задач, и представитель VMware это подтверждает.
Заключение: Рекомендации IT директорам
Ещё очень долго на форумах, в блогах и группах в соцсетях опытные специалисты с сертификатами и заполненными профилями будут говорить, что переходить на AMD рано, а какие бы неудачи ни преследовали Intel — за ними две декады доминирования в ЦОД-ах, подавляющая доля рынка и абсолютная совместимость. Это хорошо, что большая часть людей следует навязанной модели поведения, они не видят, что рынок развернулся и надо менять стратегию. Мой друг, биржевой трейдер, говорил, что чем больше людей ставят на понижение, тем сильнее актив выстрелит вверх, поэтому всё, что должен делать грамотный специалист — это брать в руки калькулятор и считать.
AMD интересен при простом сравнении стоимости сервера, его производительность в современного многопоточных приложениях позволяет значительно консолидировать сервера и даже мигрировать на односокетные сервера, снижая общее энергопотребление стоек. Интересна для анализа и ситуация с OPEX при ежегодных отчислениях за лицензии многих приложений.









Маркетинг у AMD неэффективен, и по крайней мере на российском cloud-рынке остаётся совершенно неразыгранной карта повышенной безопасности виртуальных машин с помощью изолирования памяти ВМ, о чём мы писали ранее.То есть, уже сейчас есть возможности получить на EPYC преимущества на уровне цены и функционала как при консолидации ЦОД-а, так и при построении облака с нуля.
После того, как посчитаете цены, безусловно, нужно тестировать “руками”. Для этого не обязательно брать сервер на тест. Вы можете арендовать физическую машину у cloud-провайдера, в частности, Selectel и на голом железе развернуть ваши приложения
При тестировании невычислительных приложений обратите внимание на то, что все ядра в Turboboost у AMD работают на частотах выше 3ГГц. Плюс, если есть железо под руками, попробуйте выставить в BIOS повышенный или пониженный пороги энергопотребления CPU, это полезная для больших ЦОДов функция
Михаил Дегтярев (aka LIKE OFF)
11/11.2019