
7. «Spiral Model» (спиральная модель)
«Спиральная модель» похожа на инкрементную, но с акцентом на анализ рисков. Она хорошо работает для решения критически важных бизнес-задач, когда неудача несовместима с деятельностью компании, в условиях выпуска новых продуктовых линеек, при необходимости научных исследований и практической апробации.
Спиральная модель предполагает 4 этапа для каждого витка:
- планирование;
- анализ рисков;
- конструирование;
- оценка результата и при удовлетворительном качестве переход к новому витку.
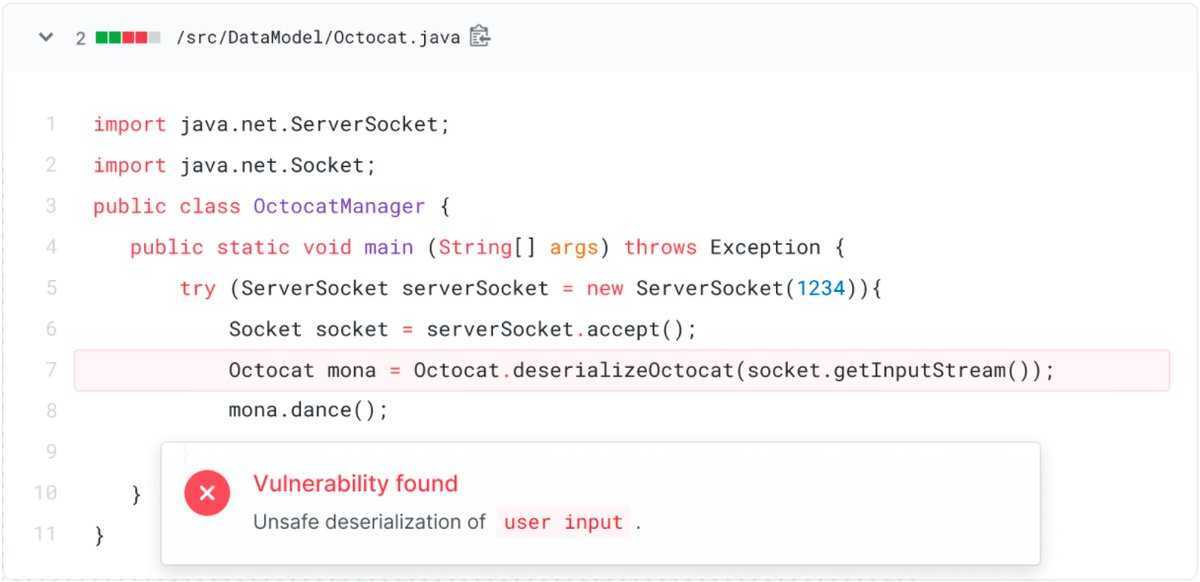
Эта модель не подойдет для малых проектов, она резонна для сложных и дорогих, например, таких, как разработка системы документооборота для банка, когда каждый следующий шаг требует большего анализа для оценки последствий, чем программирование. На проекте по разработке СЭД для ОДУ Сибири СО ЕЭС два совещания об изменении кодификации разделов электронного архива занимают в 10 раз больше времени, чем объединение двух папок программистом. Государственные проекты, в которых мы участвовали, начинались с подготовки экспертным сообществом дорогостоящей концепции, которая отнюдь не всегда бесполезна, поскольку окупается в масштабах страны.
Итог
На слайде продемонстрированы различия двух наиболее распространенных методологий.
В современной практике модели разработки программного обеспечения многовариантны. Нет единственно верной для всех проектов, стартовых условий и моделей оплаты. Даже столь любимая всеми нами Agile не может применяться повсеместно из-за неготовности некоторых заказчиков или невозможности гибкого финансирования. Методологии частично пересекаются в средствах и отчасти похожи друг на друга. Некоторые другие концепции использовались лишь для пропаганды собственных компиляторов и не привносили в практику ничего нового.
15 прорывных бизнес-моделей
Большинство моделей, которые сейчас кажутся стандартными, когда-то были прорывными.
Перечислили 15 таких моделей организации бизнеса:
1. Шеринговая экономика
Сейчас люди меньше покупают собственные квартиры из тех соображений, что не хотят надолго останавливаться на одном месте и городе. Поэтому всё больше становится популярной идея с временной арендой. Шеринг-экономика — это коллективное использование товаров или услуг. Тем, кто их предоставляет, удобно и выгодно делиться активом за деньги. В качестве актива выступает что угодно: от автомобилей до гаджетов.
2. Партнерская программа
3. Комиссия
Посреднические бизнесы делают сделку легче и успешнее. Они берут плату за операции либо с покупателем, либо с продавцом. Так делают, например, в агентствах недвижимости.
4. Кастомизация
Модель, когда производители дополняют уже готовые продукты и услуги элементами, которые подстраивают индивидуально под покупателя.
5. Краудсорсинг
По сути, это поиск решения проблем с помощью посторонних людей. Они делятся своими знаниями и опытом, а их советы в перспективе помогают бизнесу развиваться.


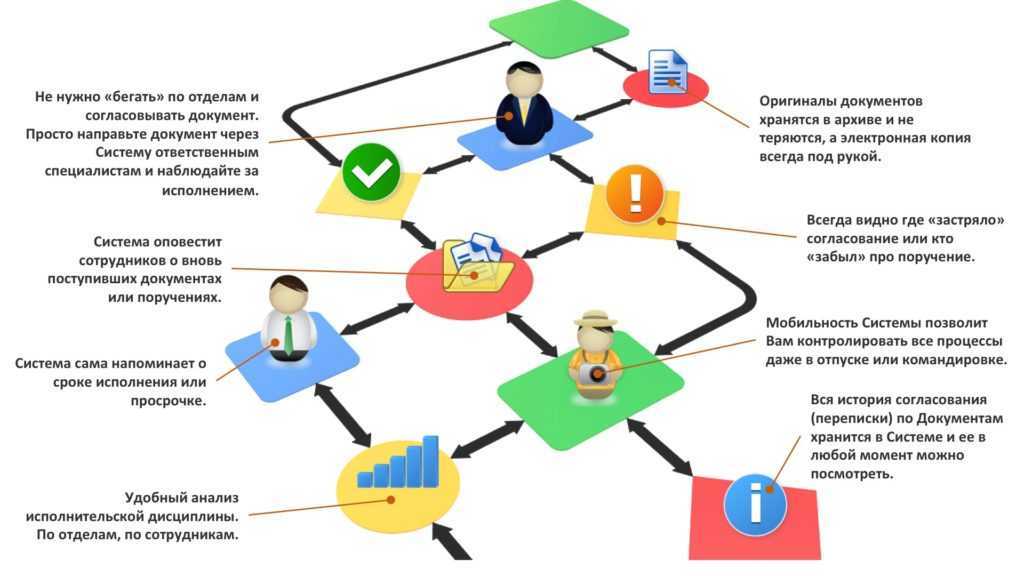
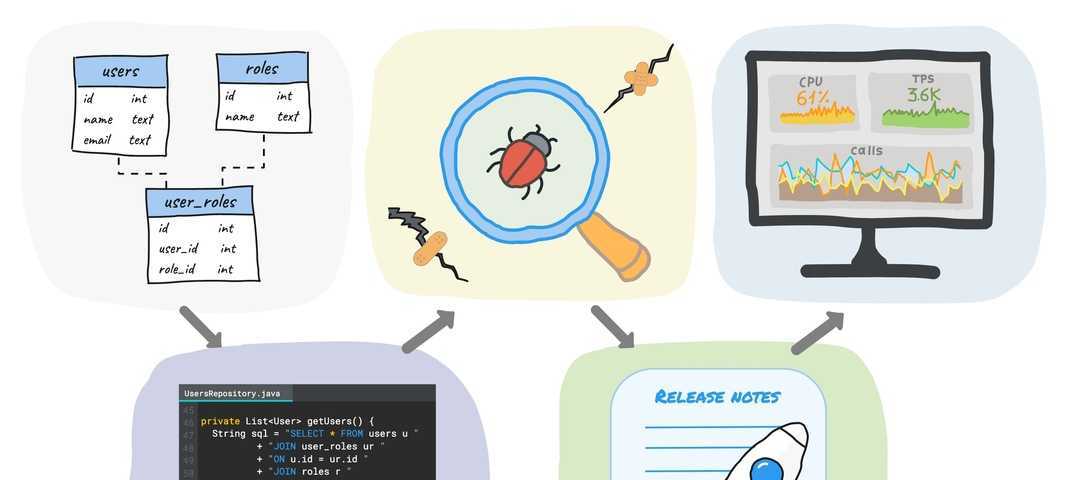
6. Работа без посредников
Модель учитывает, что вы напрямую предлагаете товары покупателям. Это снижает расходы и формирует лояльные отношения.
7. Дробление
Один из мощных вариантов — совместная аренда, когда группа людей покупает лишь часть помещения или имущества.
8. Франшиза
Это модель, при которой одна сторона продаёт другой уже разработанный план ведения бизнеса. С помощью модели новые владельцы держатся на высоком уровне на рынке.
9. Freemium
Здесь вы бесплатно предлагаете часть продукта и берёте деньги за дополнительные опции. Так можно получить свободный доступ к неограниченному использованию базовых функций.
10. Лизинг
Лизинг нужен в случае, когда дорогостоящие товары приобрести не получается, а вот вариант с временной арендой подходит. Отличается от шеринга тем, что здесь после использования имущества есть вариант с его последующим выкупом.
11. Low-touch
Это модель организации бизнеса, когда предприятие предоставляет меньшее количество услуг с условием, что покупатель приобретет дополнительные или сделает что-то сам.
12. Маркетплейс
Электронные гипермаркеты дают возможность выставлять продукт на продажу и предлагать покупателям доступные инструменты для взаимодействия с продавцами.
С помощью этой модели можно получить доход из нескольких источников, включая сборы с покупателя или продавца за удачную сделку, дополнительные услуги. Преимущество в том, что модель подходит как для товаров, так и для услуг.



13. «Бритва и лезвие»
Это модель, в которой один элемент товара продается по сниженной цене или даже отдаётся бесплатно. Это делается для того, чтобы, например, увеличить продажи расходных материалов. Вспомним компании, которые специализируются на бритвах: они дарят часть товара с учетом, что позже люди станут постоянными покупателями большого количества лезвий.
14. Обратный аукцион
Эта модель разрешает самим клиентам назначать цену товарам, которую могут заплатить. Тут уместен торг при продаже товара или услуги, в котором выигрывает тот, кто озвучивает меньшую сумму. И продавцы соглашаются на неё.
15. Подписка
Эта модель удерживает клиента долгое время и возвращает его, чтобы совершить повторные покупки. Так, например, действуют подписки на онлайн-кинотеатры, стриминговые сервисы.
Обучающая выборка действительно не репрезентативна
Бывает, что источником нерепрезентативности выборки являются не изменения во времени, а особенности процесса, породившего данные. У банка, где я работал, раньше существовала политика: нельзя выдавать кредиты людям, у которых платежи по текущим долгам превышают 40% дохода. С одной стороны, это разумно, ибо высокая кредитная нагрузка часто приводит к банкротству, особенно в кризисные времена. С другой стороны, и доход, и платежи по кредитам мы можем оценивать лишь приближённо. Возможно, у части наших несложившихся клиентов дела на самом деле были куда лучше. Да и в любом случае, специалист, который зарабатывает 200 тысяч в месяц, и 100 из них отдаёт в счёт ипотеки, может быть перспективным клиентом. Отказать такому в кредитной карте — потеря прибыли. Можно было бы надеяться, что модель будет хорошо ранжировать клиентов даже с очень высокой кредитной нагрузкой… Но это не точно, ведь в обучающей выборке нет ни одного такого!
Мне повезло, что за три года до моего прихода коллеги ввели простое, хотя и страшноватое правило: примерно 1% случайно отобранных заявок на кредитки одобрять в обход почти всех политик. Этот 1% приносил банку убытки, но позволял получать репрезентативные данные, на которых можно обучать и тестировать любые модели. Поэтому я смог доказать, что даже среди вроде бы очень закредитованных людей можно найти хороших клиентов. В результате мы начали выдавать кредитки людям с оценкой кредитной нагрузки от 40% до 90%, но с более жёстким порогом отсечения по предсказанной вероятности дефолта.
Если бы подобного потока чистых данных не было, то убедить менеджмент, что модель нормально ранжирует людей с нагрузкой больше 40%, было бы сложно. Наверное, я бы обучил её на выборке с нагрузкой 0-20%, и показал бы, что на тестовых данных с нагрузкой 20-40% модель способна принять адекватные решения. Но узенькая струйка нефильтрованных данных всё-таки очень полезна, и, если цена ошибки не очень высока, лучше её иметь. Подобный совет даёт и Мартин Цинкевич, ML-разработчик из Гугла, в своём руководстве по машинному обучению. Например, при фильтрации электронной почты 0.1% писем, отмеченных алгоритмом как спам, можно всё-таки показывать пользователю. Это позволит отследить и исправить ошибки алгоритма.
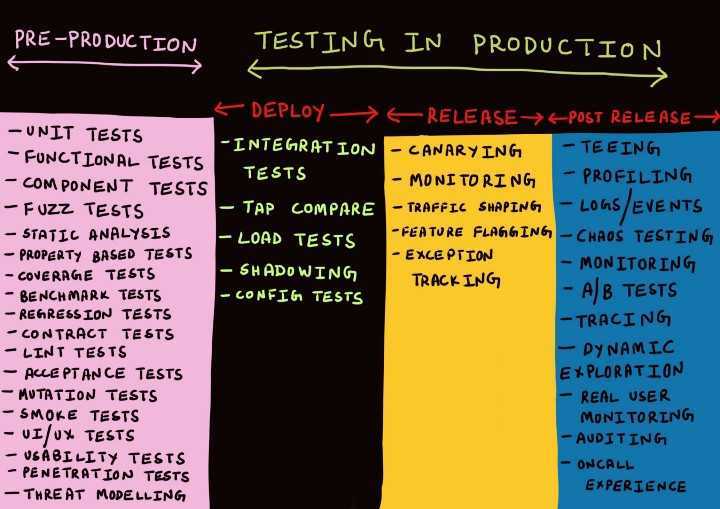
Зачем нужно тестирование в продакшене, если его можно выполнять на стейджинге?
GDPRPCIHIPAA
- Размер стейджинг-кластера (если это можно назвать «кластером» — иногда это просто один сервер под видом кластера);
- Тот факт, что на стейджинге обычно используется кластер гораздо меньшего масштаба, также означает, что параметры конфигурации почти для каждого сервиса будут различаться. Это относится к конфигурациям балансировщиков нагрузки, баз данных и очередей, например, числу дескрипторов открытых файлов, числу открытых подключений к базе данных, размеру пула потоков и пр. Если конфигурация хранится в базе данных или хранилище данных типа «ключ-значение» (например, Zookeeper или Consul), эти вспомогательные системы тоже должны присутствовать в стейджинговой среде;
- Число оперативных подключений, обрабатываемых stateless-службой, или способ повторного использования TCP-соединений прокси-сервером (если эта процедура вообще выполняется);
- Недостаток мониторинга на стейджинге. Но даже если мониторинг осуществляется, некоторые сигналы могут оказаться совершенно неточными, так как отслеживается среда, отличная от рабочей. Например, даже если выполняется мониторинг задержки запроса MySQL или времени отклика, трудно определить, содержит ли новый код запрос, который может инициировать полное сканирование таблицы в MySQL, так как гораздо быстрее (а иногда даже предпочтительнее) выполнить полное сканирование маленькой таблицы, используемой в тестовой базе данных, нежели производственной базы данных, где запрос может иметь совершенно другой профиль производительности.
абсолютноединственным
V модель — разработка через тестирование
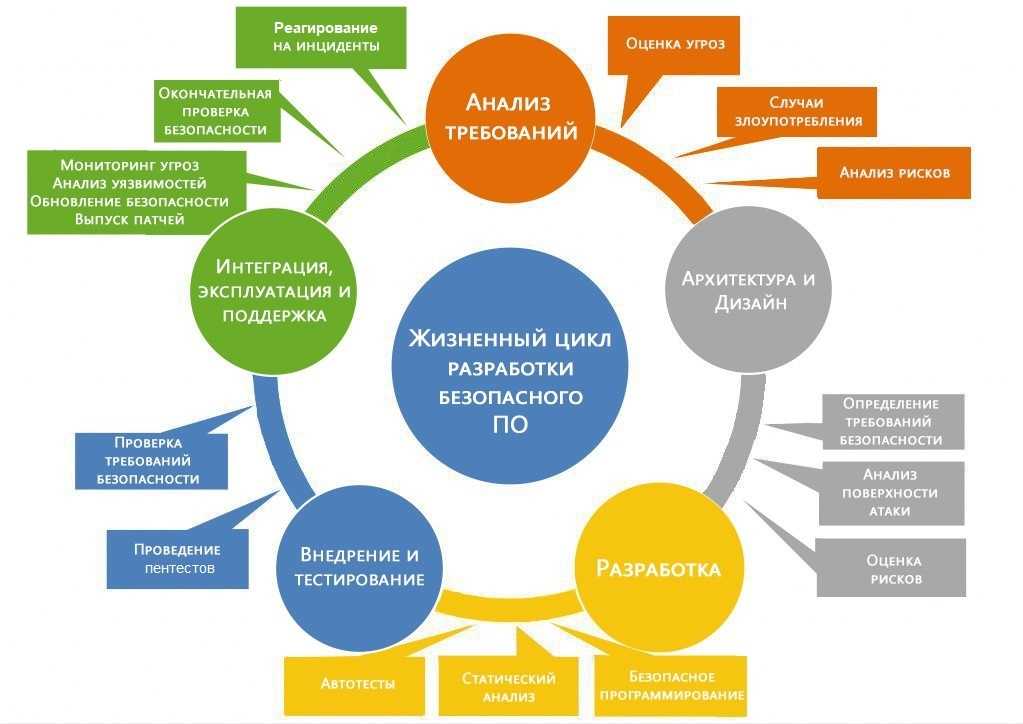
Данная модель имеет более приближенный к современным методам алгоритм, однако все еще имеет ряд недостатков. Является одной из основных практик экстремального программирования и предполагает регулярное тестирование продукта во время разработки.
V-модель обеспечивает поддержку в планировании и реализации проекта. В ходе проекта ставятся следующие задачи:• Минимизация рисков: V-образная модель делает проект более прозрачным и повышает качество контроля проекта путём стандартизации промежуточных целей и описания соответствующих им результатов и ответственных лиц. Это позволяет выявлять отклонения и риски в проекте на ранних стадиях и улучшает качество управления проектов, уменьшая риски.• Повышение и гарантии качества: V-Model —стандартизованная модель разработки, что позволяет добиться от проекта результатов желаемого качества. Промежуточные результаты могут быть проверены на ранних стадиях. Универсальное документирование облегчает читаемость, понятность и проверяемость.• Уменьшение общей стоимости проекта: ресурсы на разработку, производство, управление и поддержку могут быть заранее просчитаны и проконтролированы. Получаемые результаты также универсальны и легко прогнозируются. Это уменьшает затраты на последующие стадии и проекты.• Повышение качества коммуникации между участниками проекта: универсальное описание всех элементов и условий облегчает взаимопонимание всех участников проекта. Таким образом, уменьшаются неточности в понимании между пользователем, покупателем, поставщиком и разработчиком.







5. «Agile Model» (гибкая методология разработки)
В «гибкой» методологии разработки после каждой итерации заказчик может наблюдать результат и понимать, удовлетворяет он его или нет. Это одно из преимуществ гибкой модели. К ее недостаткам относят то, что из-за отсутствия конкретных формулировок результатов сложно оценить трудозатраты и стоимость, требуемые на разработку. Экстремальное программирование (XP) является одним из наиболее известных применений гибкой модели на практике.
В основе такого типа — непродолжительные ежедневные встречи — «Scrum» и регулярно повторяющиеся собрания (раз в неделю, раз в две недели или раз в месяц), которые называются «Sprint». На ежедневных совещаниях участники команды обсуждают:
- отчёт о проделанной работе с момента последнего Scrum’a;
- список задач, которые сотрудник должен выполнить до следующего собрания;
- затруднения, возникшие в ходе работы.
Методология подходит для больших или нацеленных на длительный жизненный цикл проектов, постоянно адаптируемых к условиям рынка. Соответственно, в процессе реализации требования изменяются. Стоит вспомнить класс творческих людей, которым свойственно генерировать, выдавать и опробовать новые идеи еженедельно или даже ежедневно. Гибкая разработка лучше всего подходит для этого психотипа руководителей.
Когда использовать Agile?
- Когда потребности пользователей постоянно меняются в динамическом бизнесе.
- Изменения на Agile реализуются за меньшую цену из-за частых инкрементов.
- В отличие от модели водопада, в гибкой модели для старта проекта достаточно лишь небольшого планирования.
Каскадная модель (waterfall)
Рис. 1.2. Каскадная (водопадная) модель
Особенности каскадной модели:
— высокий уровень формализации процессов;— большое количество документации;— жесткая последовательность этапов жизненного цикла без возможности возврата на предыдущий этап.Минусы:• Waterfall-проект должен постоянно иметь актуальную документацию. Обязательная актуализация проектной документации. Избыточная документация.• Очень не гибкая методология.• Может создать ошибочное впечатление о работе над проектом (например, фраза «45% выполнено» не несёт за собой никакой полезной информации, а является всего лишь инструментов для менеджера проекта).• У заказчика нет возможности ознакомиться с системой заранее и даже с «Пилотом» системы.• У пользователя нет возможности привыкать к продукту постепенно.• Все требования должны быть известны в начале жизненного цикла проекта.• Возникает необходимость в жёстком управлении и регулярном контроле, иначе проект быстро выбьется из графиков.• Отсутствует возможность учесть переделку, весь проект делается за один раз.Плюсы:• Высокая прозрачность разработки и фаз проекта.• Чёткая последовательность.• Стабильность требований.• Строгий контроль менеджмента проекта.• Облегчает работу по составлению плана проекта и сбора команды проекта.• Хорошо определяет процедуру по контролю качества.
Бонус: старое интервью
— Вы известны и как автор прорвы ответов на Stack Overflow, и как автор книги «C# in Depth», и как спикер технических конференций, при этом у вас есть основная работа разработчика, и, наконец, вы отец и муж. Как вообще возможно совмещать такое количество ролей?— Говоря о переключении, у вас есть какие-то определенные стратегии тайм-менеджмента?— Да и потом, если следовать вашему пути, то получишь не работу своей мечты, а работу вашей мечты.— Возвращаясь к теме множества ролей по жизни: а помогают ли эти роли друг другу? У вас был интересный твит про «talk-driven development»: во время работы над кодом полезно сочинять доклад о том, что делаешь, потому что если не можешь хорошо объяснить свои решения, то и с кодом проблемы. Есть ли ещё такие пересечения?кейноуте— Это ваш первый раз в России. Помимо конференции, вы увидели немногое но всё равно спросим: соответствует ли увиденное вашим ожиданиям?— Есть всё, что предлагают, не обязательно!— Есть ли какой-то вопрос, на который вы хотели бы ответить, но который вам еще никогда не задавали?спросили— Спасибо за такие подробные ответы.
Новое интервью: как 2020-й соотносится с 2017-м
.NET в целом
— В 2017-м вы очень оптимистично говорили о перспективах .NET, ожидая рост популярности. А как теперь оцениваете популярность: она превзошла ваши ожидания или не оправдала их?— В 2017-м из-за .NET Core весь .NET-мир был в переходном состоянии. А теперь, когда пыль улеглась, как вам видится текущее состояние экосистемы?— А есть ли какие-то сложности или недостатки в .NET Core, которые за эти три года не были исправлены?— А чего вы теперь ждёте от будущего? Что произойдёт с .NET в следующие три года? В 2023-м проверим 
Новые версии C#
— В прошлый раз вы сказали нам, что глубоко погрузились в C# 7, работая над новым изданием книги «C# in Depth». А насколько имеете дело с C# 8 и планируете ли ещё одно издание книги?— А есть ли у вас в C# 8 любимая фича?— Что вы в целом думаете про C# 8? Это именно то, что разработчикам было нужно, или вы на месте Microsoft сделали бы всё иначе?— Если вы следите за работой над C# 9, что-нибудь по его поводу думаете?
Stack Overflow
— Как за три года изменилась ситуация с качеством вопросов? Стало лучше или хуже?— Со временем что-то меняется и на самом сайте, и в сложившемся там сообществе. Что вам кажется важными изменениями?— Существует проблема, когда ответ уже устарел, но он помечен как правильный автором вопроса, и на него попадают новые пользователи. Становится ли эта проблема острее с годами, когда всё больше ответов устаревают?— Есть ли что-то, что бы вам хотелось, чтобы произошло со Stack Overflow в следующие три года? Что сделало бы его лучше?— А что, по-вашему, произойдёт на самом деле?
Напоследок
— А что хочется посоветовать сейчас?— Многие онлайн-дискуссии о diversity выглядят базарными перепалками. Кажется ли вам, что, помимо самих вопросов diversity, есть отдельная проблема обсуждения этих вопросов? У вас получается говорить об этом куда спокойнее — можете ли дать какой-то совет по уравновешенному подходу?— Каким бы вы хотели видеть мир IT в 2023-м?— А каким мир IT окажется на самом деле?
Важные моменты при использовании водопадной методологии
Когда дело доходит до разработки Waterfall, очень важно, чтобы разработчики программного обеспечения могли эффективно направлять и консультировать клиентов, чтобы позже обойти все эти проблемы. Часто самый критичный аспект применения каскадной модели жизненного цикла – то, что клиенты действительно не знают, чего они хотят на самом деле
Во многих случаях подлинное двустороннее взаимодействие между разработчиками и клиентами не происходит до тех пор, пока клиент не увидит модель в действии.
Для сравнения, в Agile development клиент может увидеть фрагменты рабочего кода, которые были созданы в процессе работы над проектом. В отличие от Scrum, который делит проекты на отдельные спринты, Waterfall всегда фокусируется на конечной цели. Если у вашей команды есть конкретная цель с четкой конечной датой, Waterfall устранит риск не уложиться в срок, когда вы будете работать над ней. Исходя из этих плюсов и минусов, разработка Waterfall обычно рекомендуется для проектов, которые, скорее всего, не изменятся либо нуждаются в новых разработках в течение жизненного цикла проекта.


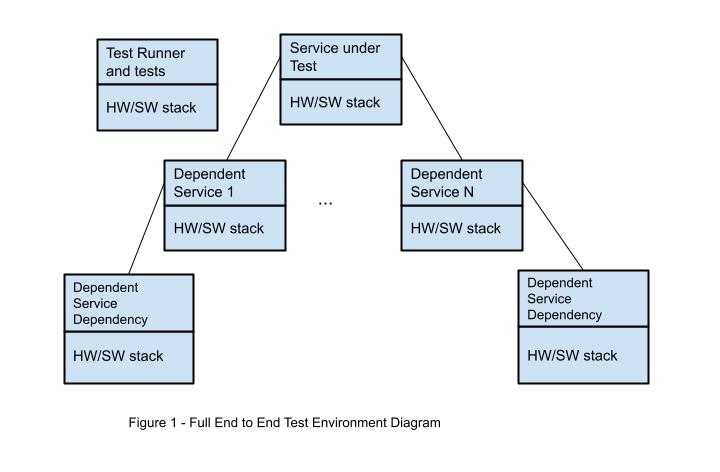
Модель очень трудно внедрить
Если модель основана на данных «из будущего», с этим вряд ли что-то можно поделать. Но часто бывает так, что даже с доступными данными внедрение модели даётся нелегко. Настолько нелегко, что внедрение затягивается на неопределённый срок из-за нехватки трудовых ресурсов на это. Что же так долго делают разработчики, если модель уже создана?
Скорее всего, они переписывают весь код с нуля. Причины на это могут быть совершенно разные. Возможно, вся их система написана на java, и они не готовы пользоваться моделью на python, ибо интеграция двух разных сред доставит им даже больше головной боли, чем переписывание кода. Или требования к производительности так высоки, что весь код для продакшна может быть написан только на C++, иначе модель будет работать слишком медленно. Или предобработку признаков для обучения модели вы сделали с использованием SQL, выгружая их из базы данных, но в бою никакой базы данных нет, а данные будут приходить в виде json-запроса.
Если модель создавалась в одном языке (скорее всего, в python), а применяться будет в другом, возникает болезненная проблема её переноса. Есть готовые решения, например, формат PMML, но их применимость оставляет желать лучшего. Если это линейная модель, достаточно сохранить в текстовом файле вектор коэффициентов. В случае нейросети или решающих деревьев коэффициентов потребуется больше, и в их записи и чтении будет проще ошибиться. Ещё сложнее сериализовать полностью непараметрические модели, в частности, сложные байесовские. Но даже это может быть просто по сравнению с созданием признаков, код для которого может быть совсем уж произвольным. Даже безобидная функция в разных языках программирования может означать разные вещи, что уж говорить о коде для работы с картинками или текстами!
Даже если с языком программирования всё в порядке, вопросы производительности и различия в формате данных в учении и в бою остаются. Ещё один возможный источник проблем: аналитик при создании модели активно пользовался инструментарием для работы с большими таблицами данных, но в бою прогноз необходимо делать для каждого наблюдения по отдельности. Многие действия, совершаемые с матрицей n*m, с матрицей 1*m проделывать неэффективно или вообще бессмысленно. Поэтому аналитику полезно с самого начала проекта готовиться принимать данные в нужном формате и уметь работать с наблюдениями поштучно. Мораль та же, что и в предыдущем разделе: начинайте тестировать весь пайплайн как можно раньше!
Разработчикам и админам продуктивной системы полезно с начала проекта задуматься о том, в какой среде будет работать модель. В их силах сделать так, чтобы код data scientist’a мог выполняться в ней с минимумом изменений. Если вы внедряете предсказательные модели регулярно, стоит один раз создать (или поискать у внешних провайдеров) платформу, обеспечивающую управление нагрузкой, отказоустойчивость, и передачу данных. На ней любую новую модель можно запустить в виде сервиса. Если же сделать так невозможно или нерентабельно, полезно будет заранее обсудить с разработчиком модели имеющиеся ограничения. Быть может, вы избавите его и себя от долгих часов ненужной работы.
Модель нестабильная
Бывает, что модель прошла все тесты, и была внедрена без единой ошибки. Вы смотрите на первые решения, которые она приняла, и они кажутся вам осмысленными. Они не идеальны — 17 партия пива получилась слабоватой, а 14 и 23 — очень крепкими, но в целом всё неплохо. Проходит неделя-другая, вы продолжаете смотреть на результаты A/B теста, и понимаете, что слишком крепких партий чересчур много. Обсуждаете это с заказчиком, и он объясняет, что недавно заменил резервуары для кипячения сусла, и это могло повысить уровень растворения хмеля. Ваш внутренний математик возмущается «Да как же так! Вы мне дали обучающую выборку, не репрезентативную генеральной совокупности! Это обман!». Но вы берёте себя в руки, и замечаете, что в обучающей выборке (последние три года) средняя концентрация растворенного хмеля не была стабильной. Да, сейчас она выше, чем когда-либо, но резкие скачки и падения были и раньше. Но вашу модель они ничему не научили.
Другой пример: доверие сообщества финансистов к статистическим методам было сильно подорвано после кризиса 2007 года. Тогда обвалился американский ипотечный рынок, потянув за собой всю мировую экономику. Модели, которые тогда использовались для оценки кредитных рисков, не предполагали, что все заёмщики могут одновременно перестать платить, потому что в их обучающей выборке не было таких событий. Но разбирающийся в предмете человек мог бы мысленно продолжить имеющиеся тренды и предугадать такой исход.
Бывает, что поток данных, к которым вы применяете модель, стационарен, т.е. не меняет своих статистических свойств со временем. Тогда самые популярные методы машинного обучения, нейросетки и градиентный бустинг над решающими деревьями, работают хорошо. Оба этих метода основаны на интерполяции обучающих данных: нейронки — логистическими кривыми, бустинг — кусочно-постоянными функциями. И те, и другие очень плохо справляются с задачей экстраполяции — предсказания для X, лежащих за пределами обучающей выборки (точнее, её выпуклой оболочки).
Некоторые более простые модели (в том числе линейные) экстраполируют лучше. Но как понять, что они вам нужны? На помощь приходит кросс-валидация (перекрёстная проверка), но не классическая, в которой все данные перемешаны случайным образом, а что-нибудь типа TimeSeriesSplit из sklearn. В ней модель обучается на всех данных до момента t, а тестируется на данных после этого момента, и так для нескольких разных t. Хорошее качество на таких тестах даёт надежду, что модель может прогнозировать будущее, даже если оно несколько отличается от прошлого.
Иногда внедрения в модель сильных зависимостей, типа линейных, оказывается достаточно, чтобы она хорошо адаптировалась к изменениям в процессе. Если это нежелательно или этого недостаточно, можно подумать о более универсальных способах придания адаптивности. Проще всего калибровать модель на константу: вычитать из прогноза его среднюю ошибку за предыдущие n наблюдений. Если же дело не только в аддитивной константе, при обучении модели можно перевзвесить наблюдения (например, по принципу экспоненциального сглаживания)
Это поможет модели сосредоточить внимание на самом недавнем прошлом
Даже если вам кажется, что модель просто обязана быть стабильной, полезно будет завести автоматический мониторинг. Он мог бы описывать динамику предсказываемого значения, самого прогноза, основных факторов модели, и всевозможных метрик качества. Если модель действительно хороша, то она с вами надолго. Поэтому лучше один раз потрудиться над шаблоном, чем каждый месяц проверять перформанс модели вручную.

6. «Iterative Model» (итеративная или итерационная модель)
Итерационная модель жизненного цикла не требует для начала полной спецификации требований. Вместо этого, создание начинается с реализации части функционала, становящейся базой для определения дальнейших требований. Этот процесс повторяется. Версия может быть неидеальна, главное, чтобы она работала. Понимая конечную цель, мы стремимся к ней так, чтобы каждый шаг был результативен, а каждая версия — работоспособна.
На диаграмме показана итерационная «разработка» Мона Лизы. Как видно, в первой итерации есть лишь набросок Джоконды, во второй — появляются цвета, а третья итерация добавляет деталей, насыщенности и завершает процесс. В инкрементной же модели функционал продукта наращивается по кусочкам, продукт составляется из частей. В отличие от итерационной модели, каждый кусочек представляет собой целостный элемент.
Примером итерационной разработки может служить распознавание голоса. Первые исследования и подготовка научного аппарата начались давно, в начале — в мыслях, затем — на бумаге. С каждой новой итерацией качество распознавания улучшалось. Тем не менее, идеальное распознавание еще не достигнуто, следовательно, задача еще не решена полностью.
Когда оптимально использовать итеративную модель?
- Требования к конечной системе заранее четко определены и понятны.
- Проект большой или очень большой.
- Основная задача должна быть определена, но детали реализации могут эволюционировать с течением времени.
Заключение
Я прошёлся по некоторым из основных провалов, с которыми сталкивался при создании и встраивании в бизнес предсказательных моделей. Чаще всего это проблемы не математического, а организационного характера: модель вообще не нужна, или построена по кривой выборке, или есть сложности со встраиванием её в имеющиеся процессы и системы. Снизить риск таких провалов можно, если придерживаться простых принципов:
- Используйте разумные и измеримые меры точности прогноза и экономического эффекта
- Начиная с первого прототипа, тестируйтесь на упорядоченном по времени потоке данных
- Тестируйте весь процесс, от подготовки данных до принятия решения, а не только прогноз
Надеюсь, кому-то этот текст поможет получше присмотреться к своему проекту и избежать глупых ошибок.