
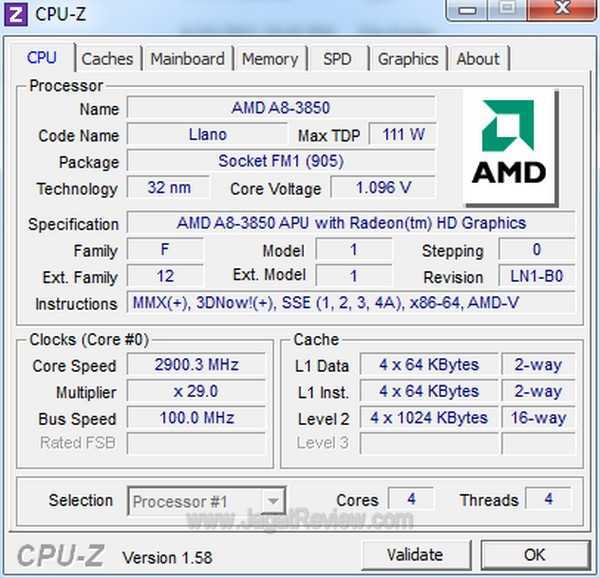
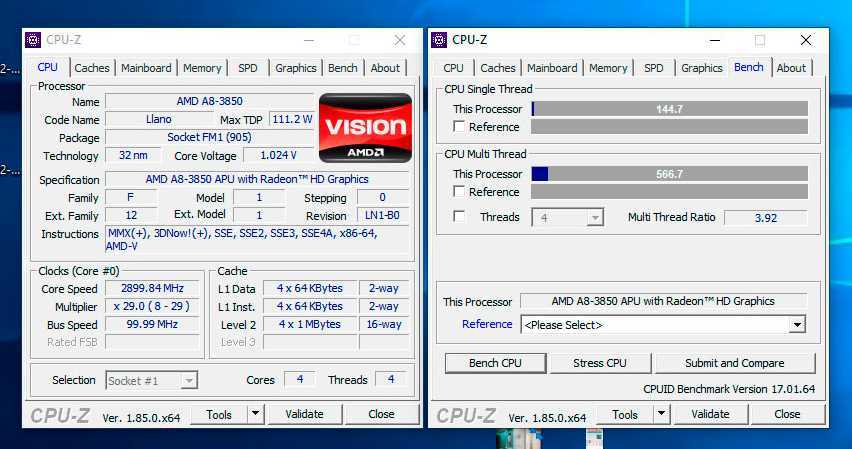
Характеристики AMD A8 3850
Функции
| Наличие NX-bit (XD-bit) | Да |
|---|---|
| Поддержка виртуализации | Да |
| Поддерживаемые инструкции | 3DNow! AMD-V AMD64 MMX SSE SSE2 SSE3 SSE4a |
| Поддержка динамического масштабирования частоты (CPU Throttling) | Да |
Детали и особенности
| Архитектура | x86-64 |
|---|---|
| Потоки | 4 |
| Кэш второго уровня (L2) | 4 MB |
| Кэш второго уровня на ядро (L2) | 1 MB/ядро |
| Кэш третьего уровня (L3) | 1 MB |
| Кэш третьего уровня на ядро (L3) | 0.25 MB/ядро |
| Технологический процесс | 32 нм |
| Количество транзисторов | 1,178,000,000 |
| Максимум процессоров | 1 |
| Размер матрицы | 228 mm² |
| Диапазон напряжения | 0.91 — 1.41V |
| Рабочая температура | Неизвестно — 72.7°C |
Разгон A8 3850
| Тактовая частота при разгоне | 3.54 GHz |
|---|---|
| Тактовая частота при разгоне с водным охлаждением | 2.9 GHz |
| PassMark (Overclocked) | 2,465.8 |
| Тактовая частота при разгоне с воздушным охлаждением | 3.54 GHz |
Потребляемая мощность
| Энергопотребление | 100W |
|---|---|
| Годовая стоимость электроэнергии (НЕкоммерческое использование) | 37.95 $/год |
| Годовая стоимость электроэнергии (коммерческое использование) | 107.75 $/год |
| Производительность на Вт | 1.39 pt/W |
| Энергопотребление в режиме ожидания | 62.4W |
| Пиковое энергопотребление | 123W |
| Среднее энергопотребление | 107.85W |
III. Ключевые отличия между GPU и CPU
1. Количество потоков на CPU и GPU
Архитектура центральных процессоров предполагает, что каждое физическое ядро на CPU может выполнять 2 потока вычислений при наличии 2 виртуальных ядер. В этом случае каждый поток выполняет инструкции независимо. В то же время количество потоков GPU в сотни раз больше, так как в этих процессорах используется программная модель SIMT (Single instruction, multiple threads). В этом случае группа потоков (обычно их 32) выполняет одну и ту же инструкцию. Таким образом, именно такую группу можно рассматривать в качестве эквивалента CPU потока, поэтому эту группу назвают истинным GPU потоком.
2. Способ реализации потоков на CPU и GPU
Ещё одним отличием GPU и CPU является то, как они скрывают латентность инструкций. CPU для этих целей использует внеочередное исполнение, а GPU использует ротацию истинных потоков, каждый раз запуская инструкции из разных потоков. Способ, используемый на GPU, является более эффективным при аппаратной реализации, но при этом необходимо, чтобы алгоритм был параллельным и нагрузка была высокой.
Из всего этого можно сделать вывод, что многие алгоритмы обработки изображений идеально подходят для реализации на GPU.
Gen8
- 1 FP32 ALU: EU: Subslices
- Каждый EU содержит 2 x 128-битных FPU. Один поддерживает 32-битные и 64-битные целые числа, FP16, FP32, FP64 и трансцендентные математические функции, а другой поддерживает только 32-битные и 64-битные целые числа, FP16 и FP32. Таким образом, FP16 (или 16-битное целое число) FLOPS вдвое больше FP32 (или 32-битного целого) FLOPS. Поскольку пропускная способность инструкций FP64 составляет 2 цикла, FP32 FLOPS составляет четверть от FP64 FLOPS.
- Каждый Subslice содержит 8 EU и семплер (4 текс / clk) и имеет 64 КБ общей памяти.
- Intel Quick Sync видео
- В Windows 10 общая системная память, доступная для использования графики, составляет половину системной памяти. Для Windows 8 — до 3840 МБ. В Windows 7 это примерно до 1,7 ГБ через DVMT .
| Графика | Запуск | Рынок | Процессор | Кодовое имя | Тактовая частота ( МГц ) | Базовая конфигурация 1 |
Поддержка API |
eDRAM ( МБ ) | Пропускная способность памяти ( ГБ / с ) | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Direct3D | OpenGL | OpenCL | Вулкан | ||||||||||
| HD Графика | 2015 г. | Ультрамобильный | Атом x5-Z8300 | Cherryview Braswell (Gen8LP) | 22B0 22B1 22B2 22B3 | 200-500 | 96: 12: 2 | 11.2 | 4.3 Windows 4.6 Linux ES 3.2 Linux | 2.0 Windows 1.2 Linux | 1.1 Linux | — | 12,8 |
| Атом x5-Z8500 | 200-600 | 25,6 | |||||||||||
| Атом x5-E8000 Celeron N3000 Celeron N3050 | 320-600 | ||||||||||||
| Celeron N3150 | 320-640 | ||||||||||||
| Атом x7-Z8700 | 200-600 | 128: 16: 2 | |||||||||||
| Pentium N3700 | 400-700 | ||||||||||||
| HD Графика 400 | 2016 г. | Атом x5-Z8350 | 200-500 | 96: 12: 2 | |||||||||
| Celeron N3010 Celeron N3060 | 320-600 | ||||||||||||
| Celeron N3160 | 320-640 | ||||||||||||
| Celeron J3060 Celeron J3160 | 320-700 | ||||||||||||
| HD Графика 405 | Pentium N3710 | 400-700 | 128: 16: 2 | ||||||||||
| Pentium J3710 | 400-740 | 144: 18: 2 | |||||||||||
| HD Графика | 2015 г. | Мобильный | Celeron 3205U Celeron 3755U Pentium 3805U | Бродуэлла (Gen8) | 1606 | 100–800 | 96: 12: 2 (GT1) | 12 FL 11_1 | 4.4 Windows 4.1 macOS 4.6 Linux ES 3.2 Linux | 2.0 Windows 1.2 macOS 2.1 Linux | 1.1 Linux | — | 25,6 |
| Celeron 3215U Celeron 3765U Pentium 3825U | 300–850 | ||||||||||||
| HD Графика 5300 | 2014 г. | Ультрамобильный | Core M-5Y10 Core M-5Y10a | 161E | 100–800 | 192: 24: 3 (GT2) | |||||||
| Ядро M-5Y10c | 300–800 | ||||||||||||
| Ядро М-5И70 | 100–850 | ||||||||||||
| Ядро М-5И31 | 300–850 | ||||||||||||
| Ядро M-5Y51 Ядро M-5Y71 | 300–900 | ||||||||||||
| HD Графика 5500 | 2015 г. | Мобильный | Core i3-5005U Core i3-5015U | 1616 | 300–850 | 184: 23: 3 (GT2) | |||||||
| Core i3-5010U Core i3-5020U | 300–900 | ||||||||||||
| Core i5-5200U Core i5-5300U | 192: 24: 3 (GT2) | ||||||||||||
| Core i7-5500U Core i7-5600U | 300–950 | ||||||||||||
| HD Графика 5600 | Мобильный | Core i7-5700EQ | 1612 | 300–1000 | |||||||||
| Core i7-5700HQ | 300–1050 | ||||||||||||
| HD Графика P5700 | Мобильный | Xeon E3-1258L v4 | ? | 700–1000 | |||||||||
| HD Графика 6000 | Мобильный | Core i5-5250U | 1626 | 300–950 | 384: 48: 6 (GT3) | ||||||||
| Core i5-5350U Core i7-5550U Core i7-5650U | 300–1000 | ||||||||||||
| Ирис Графика 6100 | Мобильный | Core i3-5157U | 162B | 300–1000 | |||||||||
| Core i5-5257U | 300–1050 | ||||||||||||
| Core i5-5287U Core i7-5557U | 300–1100 | ||||||||||||
| Ирис Про Графика 6200 | Рабочий стол | Core i5-5575R | 1622 | 300–1050 | 128 | ||||||||
| Core i5-5675C Core i5-5675R | 300–1100 | ||||||||||||
| Core i7-5775C Core i7-5775R | 300–1150 | ||||||||||||
| Мобильный | Core i7-5850EQ | 300–1000 | |||||||||||
| Core i5-5350H | 300–1050 | ||||||||||||
| Core i7-5750HQ Core i7-5850HQ | 300–1100 | ||||||||||||
| Core i7-5950HQ | 300–1150 | ||||||||||||
| Ирис Pro Графика P6300 | Рабочая станция | Xeon E3-1278L v4 | 162A | 800–1000 | |||||||||
| Xeon E3-1265L v4 | 300–1050 | ||||||||||||
| Xeon E3-1285 v4 Xeon E3-1285L v4 | 300–1150 |
Общая информация
1.Поддерживает 64-разрядную систему
AMD A8-3850
Intel Core i5-2400
32-разрядная операционная система может поддерживать до 4 Гб оперативной памяти. 64-разрядная позволяет более 4 Гб, что повышает производительность. Она также позволяет запускать 64-разрядные приложения.
2.размер полупроводников
32nm
32nm
Меньший размер указывает на более новый процесс создания чипа.
3.тактовая частота ГП
600MHz
850MHz
Графический процессор (GPU) имеет более высокую тактовую частоту.
4.Конструктивные требования по теплоотводу (TDP)
100W
95W
Требования по теплоотводу (TDP) — это максимальное количество энергии, которое должна будет рассеять система охлаждения. Более низкое значение TDP также обычно означает меньшее энергопотребление.
5.версия PCI Express (PCIe)
2
2
PCI Express (PCIe) — это высокая скорость стандарта карты расширения, которая используется для подключения компьютера к его периферии. Новые версии поддерживают более высокую пропускную способность и предоставляют более высокую производительность.
6.температура процессора
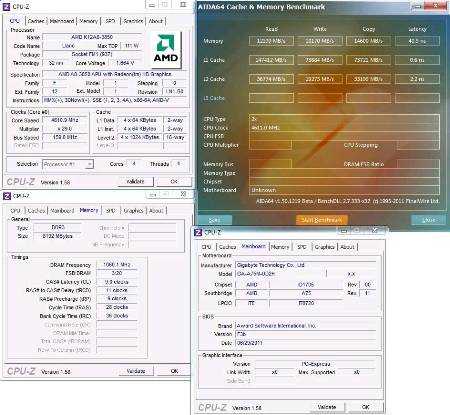







72.7°C
Неизвестно. Помогите нам, предложите стоимость. (Intel Core i5-2400)
Если процессор превышает максимальную рабочую температуру, то может произойти случайный сброс.
7.версия DirectX
11
10.1
DirectX используется в играх с новой версией, поддерживающей лучшую графику.
8.количество транзисторов
1178 миллионов
995 миллионов
Более высокое число транзисторов обычно указывает на новый, более мощный процессор.
9.версия OpenGL
4.1
3
Чем новее версия OpenGL, тем более качественная графика в играх.
IV. Преимущества GPU над CPU
Наши лабораторные исследования показали, что при сравнении идеально оптимизированного софта для GPU и для CPU (с применением AVX2), преимущество GPU имеет глобальный характер: пиковые производительности CPU и GPU аналогичного года производства отличаются обычно на порядок для 32- и 16-битных типов данных. Также на порядок отличается и пропускная способность подсистемы памяти. В следующих пунктах мы рассмотрим эту ситуацию подробнее.
Если же использовать для сравнения софт для CPU без использования инструкций AVX2, то разница в производительности может достигать 50-100 раз в пользу GPU.
Все современные GPU оснащены разделяемой памятью, которая одновременно доступна всем «вычислителям» одного мультипроцессора, что, по сути, является программно-управляемым кэшем. Он идеально подходит для алгоритмов с высокой степенью локальности
Скорость доступа к этой памяти в несколько раз превосходит возможности L1 кэша CPU.
Ещё одной важной особенностью GPU по сравнению с CPU является то, что количество доступных регистров можно менять динамически (от 64 до 256 на один поток), тем самым позволяя снижать нагрузку на подсистему памяти. Для сравнения, в архитектурах x86 и х64 используется 16 универсальных регистров и 16 AVX регистров на один поток.
Наличие нескольких специализированных аппаратных модулей на GPU для одновременной работы над совершенно разными задачами: аппаратная обработка изображений (ISP) на Jetson, асинхронное копирование в GPU и обратно, вычисления на GPU, аппаратное кодирование и декодирование видео (NVENC, NVDEC), тензорные ядра для нейросетей, OpenGL, DirectX, Vulkan для визуализации.
Но, как результат всех перечисленных выше преимуществ GPU перед CPU, за всё это приходится платить высокими требованиями к параллельности алгоритмов. Если для максимальной загрузки CPU достаточно десятков потоков, то для полной загрузки GPU нужны десятки тысяч потоков.
Встраиваемые (embedded) приложения
Следует помнить и о таком типе задач, как встраиваемые решения. Здесь GPU уже конкурируют со специализированными устройствами, такими как FPGA (программируемая пользователем вентильная матрица) и ASIC (интегральная схема специального назначения). Основным преимуществом GPU перед прочими решениями является их существенно большая гибкость. Для отдельных встраиваемых решений GPU может быть серьёзной альтернативой, так как мощные многоядерные процессоры не проходят по допустимым требованиям к размеру и энергопотреблению.









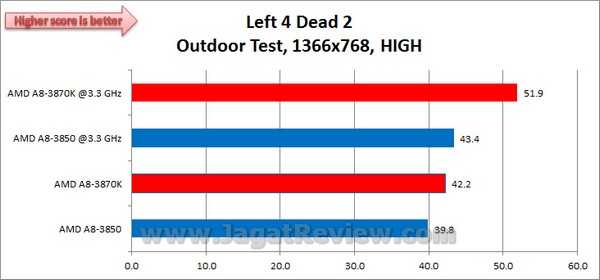
Тесты AMD A8-3850 APU
Скорость в играх
51.5
Производительность в играх и подобных приложениях, согласно нашим тестам.
Наибольшее влияние на результат оказывает производительность 4 ядер, если они есть, и производительность на 1 ядро, поскольку большинство игр полноценно используют не более 4 ядер.
Также важна скорость кэшей и работы с оперативной памятью.
Скорость в офисном использовании
53.4
Производительность в повседневной работе, например, браузерах и офисных программах.
Наибольшее влияние на результат оказывает производительность 1 ядра, поскольку большинство подобных приложений использует лишь одно, игнорируя остальные.
Аналогичным образом многие профессиональные приложения, например различные CAD, игнорируют многопоточную производительность.
Скорость в тяжёлых приложения
24.7
Производительность в ресурсоёмких задачах, загружающих максимум 8 ядер.
Наибольшее влияние на результат оказывает производительность всех ядер и их количество, поскольку большинство подобных приложений охотно используют все ядра и соответственно увеличивают скорость работы.
При этом отдельные промежутки работы могут быть требовательны к производительности одного-двух ядер, например, наложение фильтров в редакторе.
Данные получены из тестов пользователей, которые тестировали свои системы как в разгоне, так и без. Таким образом, вы видите усреднённые значения, соответствующие процессору.
Преимущества встроенных решений в играх
Итак. Для чего же нужна интегрированная карта и в чем заключаются ее отличия от дискретной.
Постараемся сделать сравнение с пояснением каждой позиции, сделав все максимально аргументировано. Начнем, пожалуй, с такой характеристики как производительность. Рассматривать и сравнивать будем наиболее актуальные на данный момент решения от Intel (HD 630 c частотой графического ускорителя от 350 до 1200 МГц) и AMD (Vega 11 с частотой 300‑1300 Мгц), а также преимущества, которые дают эти решения.
домашнего
Частота графического ускорителя AMD заметно выше, да и производительность адаптера от красных существенно выше, что говорит о следующих показателях в тех же играх:
| Игра | Настройки | Intel | AMD |
| PUBG | FullHD, низкие | 8–14 fps | 26–36 fps |
| GTA V | FullHD, средние | 15–22 fps | 55–66 fps |
| Wolfenstein II | HD, низкие | 9–14 fps | 85–99 fps |
| Fortnite | FullHD, средние | 9–13 fps | 36–45 fps |
| Rocket League | FullHD, высокие | 15–27 fps | 35–53 fps |
| CS:GO | FullHD, максимальные | 32–63 fps | 105–164 fps |
| Overwatch | FullHD, средние | 15–22 fps | 50–60 fps |
Как видите, Vega 11 – лучший выбор для недорогих «игровых» систем, поскольку показатели адаптера в некоторых случаях доходят до уровня полноценной GeForce GT 1050. Да и в большинстве сетевых баталий она показывает себя прекрасно.









На данный момент с этой графикой поставляется только процессор AMD Ryzen 2400G, но он определенно стоит внимания.
Что нужно учитывать при покупке игрового процессора
Первое, что нужно учитывать при выборе игрового процессора, это то, для чего вы собираетесь его использовать. Тот факт, что процессор является «лучшим» в одной категории, не означает, что это лучший процессор для вас.
Но, что искать в процессоре? Как узнать, что он подходит для меня? Должен ли он иметь больше ядер или более высокие скорости? Давайте рассмотрим несколько ключевых факторов, которые могут помочь вам принять решение:
Хардкорные игры
Иногда вы хотите построить мощную игровую установку, и не заботитесь о потоковой передаче или создании контента. Ваша главная задача – получить высокие цифры FPS.
Когда дело доходит до чистой игровой сборки, скорость – ваш друг. В отличие от программ и задач с высокой нагрузкой, игры не так зависят от ядер и потоков процессора. Для игр достаточно всего четырехъядерного процессора.
Большинство игр будут работать на двухъядерном процессоре, но всё больше и больше игр начинают нуждаться в четырехъядерном процессоре или выше для установки и запуска. При этом большинство современных процессоров оснащаются как минимум 4-мя ядрами.
Сочетание быстрого процессора с хорошим SSD, мощной видеокартой и качественной оперативной памятью действительно увеличит ваш FPS.
Казуальные игры
Может быть, вас не волнуют высокие цифры FPS или сохранение вашего контента для всеобщего обозрения. Возможно, вы тот тип, кто любит играть время от времени. Игры AAA – это не для вас, и вам не требуется вся эта вычислительная мощность.
Если всё, что вам нужно, – это игровая сборка, на которой будут запускаться некоторые малоинтенсивные игры и киберспортивные игры, тогда обычной игровой установки будет достаточно для ваших нужд. Как правило, обычная игровая сборка не нуждается в последних аппаратных предложениях. Это также намного доступнее, чем сборка для хардкорной игры.
При поиске «обычного» игрового процессора, вы должны искать тот, который имеет минимум четыре ядра, если позволяет ваш бюджет. Это также не обязан быть чрезвычайно быстрым.
Для трансляций
За последние пять лет усилилась тенденция к потоковой передаче и распространению игрового контента. Платформы, такие как YouTube и Twitch, в настоящее время пользуются огромной популярностью среди игрового сообщества, и всё больше людей запускает собственные стримы.
Однако, это может несколько обременять ваш процессор. Это означает, что вам нужен процессор с большим количеством ядер и потоков, больше чем в типичной хардкорной игровой сборке. Наличие большего числа ядер и потоков поможет многозадачности вашего компьютера, позволяя ему записывать вашу игру, а также обрабатывать все остальные процессы, выполняемые в фоновом режиме, без задержки!
Создание контента
Допустим, у вас уже есть подписчики на вашем канале YouTube / в аккаунте Twitch, и вы готовы поднять производство на новый уровень и начать создавать лучшие видео.
Вы решили собрать ПК, который может делать всё это. Он должен быть способен воспроизводить, транслировать и выкачивать видео хорошего качества. Это потребует большой вычислительной мощности. Вам понадобится большое количество ядер и потоков с высокими скоростями, чтобы вы могли рендерить контент как можно быстрее.
Разгон
Возможно, у вас какое-то время был игровой автомат, и вы хотите обновить его с учетом разгона. Может быть, вы хотите начать разгон и довести свою текущую систему до предела?
Если вы хотите разогнать процессор Intel, вам придется купить модель с K, например Intel i9-9900K. Но, Вам не придётся беспокоиться о процессоре AMD, все модели Ryzen (нынешняя игровая линейка AMD) разблокированы для разгона. С другой стороны, у чипов Ryzen не так много места для разгона, потому что они так хорошо оптимизированы.








Стоит ли разгонять процессор?
Вопрос разгона при обсуждении игровых процессоров и видеокарт поднимается довольно часто. Он представляет собой увеличение тактовой частоты процессора по сравнению с заводскими настройками с целью повышения его производительности. Как уже упоминалось выше, в играх важнее именно высокая частота, а не большое количество потоков. Насколько же серьезным может быть выигрыш при разгоне?
Говоря откровенно, разгон – главным образом удел энтузиастов. Для получения действительно ощутимого прироста в производительности вам потребуется топовый процессор и относительно дорогой кулер (возможно, даже система жидкостного охлаждения). Поэтому для большинства геймеров разгон не будет в приоритете при выборе процессора, так как выигрыш в производительности составит в лучшем случае несколько кадров в секунду. Кроме того, современные процессоры более чем адекватно справляются с саморазгоном, поднимая частоты при нагрузке и снижая в простое, и с дополнительным оверклокингом вы вряд ли сумеете добиться значимых успехов.
Конечно, если вы хотите заняться разгоном, никто вам не запретит. Учитывайте лишь то, что для этого потребуется соответствующий процессор (например, у Intel процессоры, поддерживающие разгон, маркируются буквой K) и довольно дорогая материнская плата с надежными элементами, способными выдержать нагрузку. Разгонять мощный процессор на бюджетной материнской плате — не самая лучшая затея: это чревато выходом оборудования из строя. Другими словами, если раньше оверклокинг можно было назвать действенным методом для повышения быстродействия компьютера с минимальными вложениями, то сейчас это, скорее, развлечение для энтузиастов, готовых тратить на него немалые деньги.
Приложение №2 — алгоритмы memory-bound и compute bound
Когда мы говорим об этих типах алгоритмов, необходимо понимать, что речь идёт о конкретной реализации алгоритма на конкретной архитектуре. У каждого процессора есть некоторая пиковая арифметическая производительность. Если реализация алгоритма может на целевом участке достигнуть пиковой производительности процессора по вычислительным инструкциям, то тогда она compute-bound, в противном случае основным ограничением станет память и реализация memory-bound.
Подсистема памяти у всех процессоров является иерархической, состоящий из нескольких уровней. Чем уровень ближе к процессору, тем он меньше по объёму и тем он быстрее. На первом уровне находится кэш данных первого уровня, а на последнем уровне оперативная память.
Алгоритм может быть изначально compute-bound на первом уровне иерархии, а затем стать memory-bound на более высоких уровнях иерархии.
Рассмотрим несколько примеров. Допустим, мы хотим сложить два массива и записать результат в третий. Можно записать это как X = Y + Z, где X, Y, Z – массивы. Допустим, мы воспользуемся инструкциями AVX для реализации на процессоре. Тогда на один элемент нам потребуется два чтения, одно суммирование и одна запись. Современный CPU может выполнить два чтения и одну запись одновременно в кэш L1. Но вместе с тем, он может выполнить и две арифметические инструкции, а мы можем воспользоваться только одной. Это значит, что алгоритм суммирования массивов является memory-bound уже на первом уровне иерархии памяти.
Рассмотрим второй алгоритм. Фильтрация изображения в окне 3×3. Фильтрация изображения основана на операции свёртки окрестности пиксела с коэффициентами фильтра. Для вычисления свёртки используется инструкция MAD (или FMA в зависимости от архитектуры). Для окна 3×3 потребуется 9 таких инструкций. Операция инструкции B = AX + B, где B – аккумулятор, накапливающий значения свёртки, A – коэффициент фильтра, X – значение пиксела. Значения A и B находятся в регистрах, а значения пиксела загружаются из памяти. В этом случае на одну инструкцию FMA требуется одна загрузка. Здесь CPU сможет за счёт двух загрузок снабжать данными два порта FMA и полностью загрузит процессор. Алгоритм можно считать compute-bound.
Давайте рассмотрим этот же алгоритм на уровне доступа к оперативной памяти. Возьмём самую экономную по памяти реализацию, когда одно чтение пиксела обновляет все окна в которые он входит. В этом случае на одну операцию чтения будет приходиться 9 инструкций FMA. Таким образом, одно ядро CPU при обработке float данных на частоте 4 ГГц потребует 2 (инструкции за такт) × 8 (float в AVX регистре) × 4 (Байта в float) × 4 (ГГц) / 9 = 28.5 ГБайт/с. Двухканальный контролер с DDR4-3200 имеет пиковую пропускную способность в 50 ГБайт/с и по расчётам он способен быть источником данных только для двух CPU ядер в этой задаче. Поэтому такой алгоритм, запущенный на 8–16 ядерном процессоре является memory-bound. Несмотря на то, что на нижнем уровне он сбалансирован.
Теперь рассмотрим этот же алгоритм при реализации на GPU. Сразу видно, что GPU имеет на уровне SM менее сбалансированную архитектуру с уклоном в вычисления. Для архитектуры Turing отношение скорости арифметических операций (во float) к скорости загрузки из Shared Memory – 2:1, для Ampere 4:1. За счёт большего количества регистров на GPU можно реализовать указанную выше оптимизацию для CPU напрямую на регистрах GPU. Это позволяет сбалансировать алгоритм даже для Ampere. И на уровне Shared Memory реализация остается compute-bound. С точки зрения памяти верхнего уровня (глобальной) расчёт для Quadro RTX 5000 (Turing) даёт следующие результаты: 64 (операций за такт) × 4 (Байт в float) × 1.7 (ГГц) / 9 = 48.3 ГБайт/с на один SM. Отношение общей пропускной способности к пропускной способности SM составит 450 / 48.3 = 9.3 раза. Общее количество SM в Quadro RTX 5000 равно 48. Т.е. и для GPU алгоритм фильтрации на высоком уровне является memory-bound.
По мере роста размера окна алгоритм становится всё более сложным и соответственно смещается в сторону compute-bound. Большинство алгоритмов обработки изображений являются memory-bound на уровне глобальной памяти. И так как пропускная способность памяти GPU во многих случаях на порядок больше чем у CPU, то это обеспечивает сопоставимый прирост производительности.
История появления
Впервые компании начали внедрять графику в собственные чипы в середине 2000‑х. Интел начали разработку еще с Intel GMA, однако данная технология довольно слабо себя показывала, а потому для видеоигр была непригодной. В результате на свет появляется знаменитая технология HD Graphics (на данный момент самый свежий представитель линейки – HD graphics 630 в восьмом поколении чипов Coffee Lake). Дебютировало видеоядро на архитектуре Westmere, в составе мобильных чипов Arrandale и десктопных – Clarkdale (2010 год).
AMD пошла иным путем. Сначала компания выкупила ATI Electronics, некогда крутого производителя видеокарт. Затем начала корпеть над собственной технологией AMD Fusion, создавая собственные APU – центральный процессор со встроенным видеоядром (Accelerated Processing Unit). Дебютировали чипы первого поколения в составе архитектуры Liano, а затем и Trinity. Ну а графика Radeon r7 series на долгое время прописалась в составе ноутбуков и нетбуков среднего класса.
Характеристики
Новая процессорная архитектура AMD под кодовым названием «Llano» сочетает в себе как вычислительное, так и графическое оборудование на одном чипе, создавая то, что AMD называет ускоренным процессором или APU. Мы уже протестировали мобильную платформу на прототипе ноутбука и обнаружили, что, хотя она не может конкурировать с процессорами Intel Sandy Bridge в 2D-приложениях, производительность 3D была на пределе.

Процессоры для настольных ПК, основанные на новой архитектуре Llano, имеют кодовое имя «Lynx», и есть четыре модели: A6-3600, A6-3650, A8-3650 и A8-3850. Каждый из этих APU имеет четыре ядра «Звезды», которые представляют собой обновленные версии ядер K10, которые можно найти в процессорах AMD Phenom II. Ядра Stars основаны на 35 нм, а не 45 нм процессах, что приводит к снижению проектной тепловой мощности (TDP) — в то время как процессоры Phenom II X4 на базе K10 имеют TDP 95 Вт для более медленных моделей и 125 Вт для Phenom II 955 и новые процессоры серии A имеют TDP 65 Вт для более медленных процессоров A6-3600 и A8-3800 и 100 Вт для A6-3650 и A8-3850. Это означает, что они работают круче, чем старые чипы, и AMD рекомендует использовать стандартные процессорные кулеры Socket AM2 или AM3. Новые чипы, однако, требуют нового разъема под названием FM1 — см. Наш обзор оснащенного FM1 Asrock A75 Pro4.







Необычно для AMD, новый процессор означает новый тип сокета
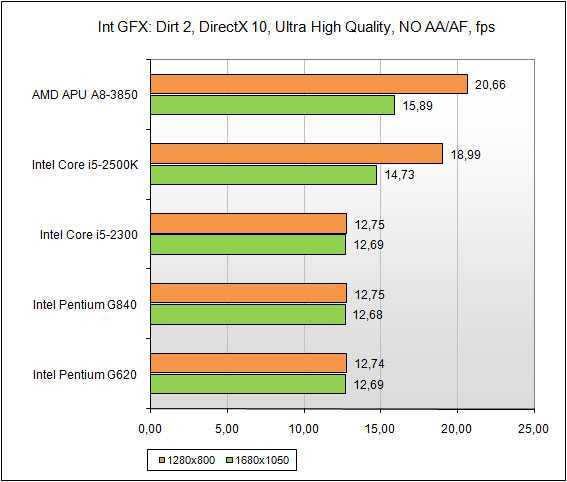
Оба процессора A6 и A8 имеют четыре ядра и 4 МБ кэш-памяти второго уровня, но основные различия заключаются в графике. Чипы A6 имеют 320 потоковых процессоров и ядро 443 МГц, в то время как A8 имеют 400 потоковых процессоров и ядро с тактовой частотой 600 МГц. Наш тест A8-3850 показал себя гораздо более способным, чем наш эталонный процессор Intel Core i5-2500K в играх. В то время как A8-3850 не смог запустить наш новый эталонный тест Dirt 3 при наших высококлассных настройках 1920×1080 с 4xAA и Ultra detail, как только мы выполнили его при наших «низких» настройках (1280×720, 4xAA, High detail), мы увидели гладкая 35 кадров в секунду. В одном тесте Intel Core i5-2500K может работать только со скоростью около 13 кадров в секунду.
У чипсета есть еще один игровой туз в рукаве. Если вы соедините процессор серии A с видеокартой AMD 6 серии, вы можете запустить их в режиме CrossFire для повышения производительности. Сама по себе минимальная цена в 4212 512 МБ AMD Radeon HD 6450 достигла 28,6 кадра в секунду в Dirt 3 при наших низких настройках, которые можно воспроизводить, но только справедливо. Как только мы включили CrossFire, частота кадров почти удвоилась до гладких и гладких 52,3 кадра в секунду. Игра даже работала с разрешением 1,920×1,080 и высокой детализацией с плавной скоростью 34,2 кадра в секунду, как только мы отключили сглаживание. Хотя эта комбинация не такая быстрая, как сама по себе более мощная карта, такая как Radeon HD 6670 за 75 фунтов стерлингов, которая достигла 47,2 кадров в секунду при разрешении 1,920×1,080, высокая детализация и отсутствие АА, это хороший способ повысить производительность к системе на базе процессоров Llano для минимальных затрат.
Итоги
Встроенная графика – отличный вариант в 3 случаях:
- вам необходима временная видеокарта, поскольку денег на внешнюю не хватило;
- система изначально задумывалась как сверхбюджетная;
- вы создаете домашнюю мультимедийную станцию (HTPC), в которой основной акцент делается именно на встроенное ядро.
Надеемся одной проблемой в вашей голове стало меньше, и теперь вы знаете, для чего производители создают свои APU.
В следующих статьях поговорим о таких терминах как виртуализация и не только. Следите за обновлениями блога, чтобы быть в курсе всех актуальных тем, связанных с железом.
Комментируйте, не стесняйтесь, делитесь в соц.сетях. Жду вас завтра на моем блоге.